
What is a Relational Database
A Database is a collection of related data, and a Relational Database is a database that has “relations”. Where, formally, a relation is a subset of a cartesian product of sets. Informally, a relation is a “table” with rows and columns. Therefore, a “Relational Database” is a database that arranges data in a tabular fashion.
The Cartesian product of two sets A and B, denoted A × B, is the set of all possible ordered pairs where the elements of A are first and the elements of B are second. In set-builder notation, A × B = {(a, b) : a ∈ A and b ∈ B}.
A relational database is a digital database based on the relational model of data proposed by E. F. Codd in 1970. There are also software systems used to maintain relational databases – these software systems are called relational database management systems (RDBMS).

In 1970 you could not write a database application without knowing a great deal about the low-level physical implementation of the data. Codd’s radical idea (1970) was to give users a model of data and a language for manipulating that data which is completely independent of the details of its physical representation/implementation. This idea then decouples development of Database Management Systems (DBMSs) from the development of database applications (at least in an idealized world) (Ref#: G).
RDMBS
So, RDBMS stands for Relational Database Management System, and we know that it’s software system used to create and manage relational databases.
As we have already covered, since an RDBMS manages relational databases, the data that these software systems manage will, therefore, be stored in tables. As we have seen, these tables are just collections of related data entries consisting of columns and rows. Within an RDBMS, all relationships will be represented by common values in related tables.
Most modern database systems are based on RDBMS principles.
Components of a DBMS
A DBMS is typically made up of various subsystems which help to preserve the integrity of performance of the system. These can include:
- DBMS engine
- User interface subsystem
- Data dictionary subsystem
- Performance management subsystem
- Data integrity management subsystem
- Backup and recovery subsystem
- Application development subsystem
- Security management subsystem
(SOURCE: Ref#: M)
ACID properties
“A transaction is a very small unit of a program and it may contain several low-level tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity” (tutorialspoint).
- Atomicity A transaction must be treated as an atomic unit meaning that either all actions are carried out or none are. Transactions must not be left partially completed. Logs needed to undo operations as required needed.
- Consistency If each transaction is consistent, and the database is initially consistent, then it is left consistent. “If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well”.
- Isolation Transactions are isolated, or protected, from the effects of other scheduled transactions.
- Durability If a transaction completes successfully, then its effects persist.
Entities, Attributes, and Relationships
“The first step in the development of a database application usually involves determining what the major elements of data to be stored are. These are referred to as entities. For example, a library database will typically contain entities such as Books, Borrowers, Librarians, Loans, Book Purchases, etc. Each of the entities identified will contain a number of properties, or attributes. For example, the entity Book will contain attributes such as Title, Author and ISBN; the entity Borrower will possess attributes such as Name, Address and Membership Number. When we have decided which entities are to be stored in a database, we also need to consider the way in which those entities are related to one another. Examples of such relationships might be, for the library system, that a Borrower can borrow a number of Books, and that a Librarian can make a number of Book Purchases. The correct identification of the entities and attributes to be stored, and the relationships between them, is an extremely important topic in database design”(Ref#: M).
ER Diagrams
Entity-Relationship (ER) modelling is a method of database design that is high-level and diagram-based.

Here we see the entities in the square boxes and relationships in the diamond shapes, with the cardinality of the relationships in the ER diagram indicated by the 1s and Ms or Ns on either side of the ins-and-outs of the diamond shapes. When we are first planning a database, we could use an ER diagram, and this might particularly be the case for small databases. When it comes to large databases we know that we will likely be de-normalizing our data, yet the ER diagram can still act as a good starting point for us in the first instance.
Relational schema
The relational schema is the primary element of the relational database. These databases are managed using language and structure that is consistent with first-order logic. This allows for database management based on entity relationships, making them easy to organize according to volume.
The term Relational Schema then refers to the meta-data that describes the structure of data within a certain domain. It is the blueprint of a database that outlines the way its structure organizes data into tables.
(https://byte-notes.com/relational-schema/)
A relational schema outlines the database relationships and structure in a relational database program. It can be displayed graphically or written in the Structured Query Language (SQL) used to build tables in a relational database.
A database schema is ultimately implemented in SQL through CREATE statements. These are commands to the database program to build (or create) tables with certain specifications. They specify which column constitutes a primary key, what type of data each column stores, and which are foreign keys referencing other tables.
Relational Algebra
Relational Algebra is generally considered to mean a simple ‘operational’ model that is useful for expressing execution plans
It has five basic operator classes, and it’s own style of notation which is used when writing down relational algebraic expressions:
1. Selection
- Selects a subset of rows
2. Projection
- Picking certain columns
3. Renaming
- Renaming attributes
4. Set theoretic operations
- The familiar operations: union, intersection, difference, …
5. Products and joins
- Combining relations in useful ways
Relational Calculus
Whilst Relational Algebra is a useful, procedural, “vendor-independent, standard mechanism for discussing the manipulation of data”, another vendor-independent means of representing the manipulation of data has been developed known as Relational Calculus, but this way is declarative.
To elaborate on this further, Relational Calculus is a non-procedural query language – it tells what to do but never explains how to do it.
“it possible to map expressions between the Algebra and the Calculus, and it has also been shown that it is possible to convert any expression in one language to an equivalent expression in the other. In this sense, the Algebra and Calculus are formally equivalent”(Ref#: M).
Normalization
“Normalized databases are designed to minimize redundancy, while denormalized databases are designed to optimize read time” (CCI Book).
In a conventional normalized database, say for a university, we might end up with data such as Courses and Teachers, the Courses table might contain a column called TeacherID, which is a foreign key to Teacher. Whilst this means that the data about the teacher like her name, address, and other details are only stored once in our database, it also means that many common queries will require joins which can prove “expensive” in term of time to run. This might have almost no impact on small databases, but on massive databases with thousands or millions of entries, it could be the difference between a solution that works well, and a terrible solution.
Denormalizing a database involves storing redundant data which means that if we know that we are going to have to repeat a particular query often we might instead choose to store particular data twice, like instead of having to look up which Teacher teaches a particular Course we could just store the teachers full name and details in the Courses table.
Large Database Design
As covered above. When we design large scalable databases, joins are generally really slow. For this reason, we absolutely must denormalize our data and we need to think about how (the aforementioned) data will be used specifically, and then we must duplicate the data into multiple tables such as to make our database as efficient and scalable as we can.
“””
As the normalisation process progresses, the number of relations required to represent the data of the application being normalised increases. This can lead to performance problems when it comes to performing queries and updates on the implemented system, because the increased number of tables require multiple JOINs to combine data from different tables. These performance problems can be a major issue in larger applications (by larger we mean both in terms of numbers of tables and quantity of data). To avoid these performance problems, it is often decided not to normalise an application all the way to fourth normal form, or, in the case of an existing application which is performing slowly, to denormalise an existing application. The process of denormalisation consists of reversing (or in the case of a new application, not carrying out in the first place) the steps to fully normalise an application. Whether this is appropriate for any given application depends critically on two factors:
- Whether the size of the application is sufficient that it will run slowly on the hardware/software platform being used.
- Whether failing to carry out certain steps in the normalisation process will compromise the requirements of the applications users.
“””(Ref#: Q).
Query optimization
“Query optimization is the part of the query process in which the database system compares different query strategies and chooses the one with the least expected cost. The query optimizer, which carries out this function, is a key part of the relational database and determines the most efficient way to access data” (Ref#: J).
Other Topics
- Indexes, multi-level index trees
- Transaction processing
- XML
- XHTML
SQL
“Virtually all relational database systems use SQL (Structured Query Language) for querying and maintaining the database” (Wikipedia).
“SQL stands for Structured Query Language, and it is the de facto standard for interacting with relational databases. Almost all database management systems you’ll come across will have an SQL implementation. SQL was standardized by the American National Standards Institute (ANSI) in 1986 and has undergone many revisions, most notably in 1992 and 1999. However, all DBMS’s do not strictly adhere to the standard defined but rather remove some features and add others to provide a unique feature set. Nonetheless, the standardization process has been helpful in giving a uniform direction to the vendors in terms of their database interaction language”(SQLPrimer).
History of SQL
- 1970 – E.F. Codd develops the relational database concept
- 1974-1979 – System R with Sequel (later called SQL) is created at the IBM Research Lab
- 1979 – Oracle markets the first relational DB with SQL
- 1981 – SQL/DS first available RDBMS system on DOS/VSE
- Others followed: INGRES(1981), IDM(1982), DG/SGL(1984), Sybase(1986)
- 1986 – The ANSI SQL was released
- 1989, 1992, 1999, 2003, 2006, 2008 – Major ANSI standard updates
- Present Day – SQL is supported by most major database vendors
Basic Data Types in SQL
|
Character types |
char, varchar |
|
Integer values |
integer, smallint |
|
Decimal numbers |
numeric, decimal |
|
Date data type |
date |
JOINs
“It is not usually very long before a requirement arises to combine information from more than one table, into one coherent query result”.
LEFT JOIN, RIGHT JOIN, INNER JOIN
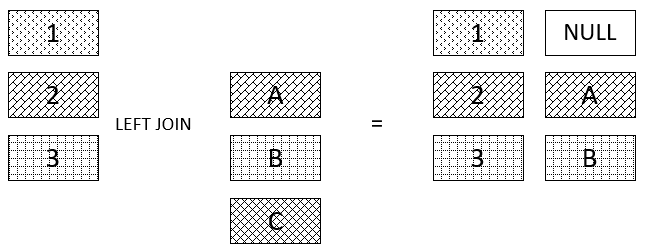
Left Join
“The LEFT JOIN clause allows you to query data from multiple tables. It returns all rows from the left table and the matching rows from the right table. If no matching rows found in the right table, NULL are used”.
Right Join
“The RIGHT JOIN combines data from two or more tables. The RIGHT JOIN starts selecting data from the right table and matching with the rows from the left table. The RIGHT JOIN returns a result set that includes all rows in the right table, whether or not have matching rows from the left table. If a row in the right table does not have any matching rows from the left table, the column of the left table in the result set will have nulls.”
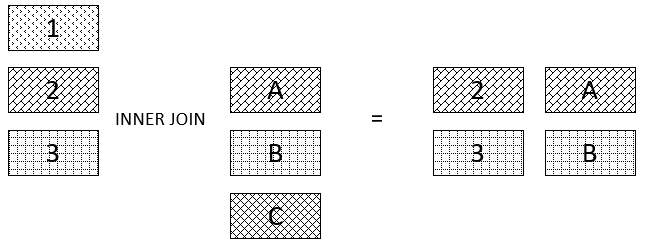
Inner Join
“The INNER JOIN clause compares each row of the table T1 with rows of table T2 to find all pairs of rows that satisfy the join predicate. If the join predicate evaluates to TRUE, the column values of the matching rows of T1 and T2 are combined into a new row and included in the result set.”
Explicit Vs Implicit Join
We can take the approach of writing our SQL using Explicit Joins or we can alternatively take the approach of using Implicit Joins, this tends to be a matter of personal preference but we should stick to one style once we pick it.
| Explicit Join | Implicit Join | ||
| SELECT CourseName, TeacherName | SELECT CourseName, TeacherName | ||
| FROM Courses INNER JOIN Teachers | FROM Courses, Teachers | ||
| ON Course.TeacherID = Teacher.TeacherID | WHERE Courses.TeacherID = | ||
| Teachers.TeacherID |
Different Flavours of SQL
“Although SQL is an ANSI (American National Standards Institute) standard, there are many different versions of the SQL language.
However, to be compliant with the ANSI standard, they all support at least the major commands (such as SELECT, UPDATE, DELETE, INSERT, WHERE) in a similar manner.
Note: Most of the SQL database programs also have their own proprietary extensions in addition to the SQL standard!”(http://w3schools.sinsixx.com/sql/sql_intro.asp.htm).
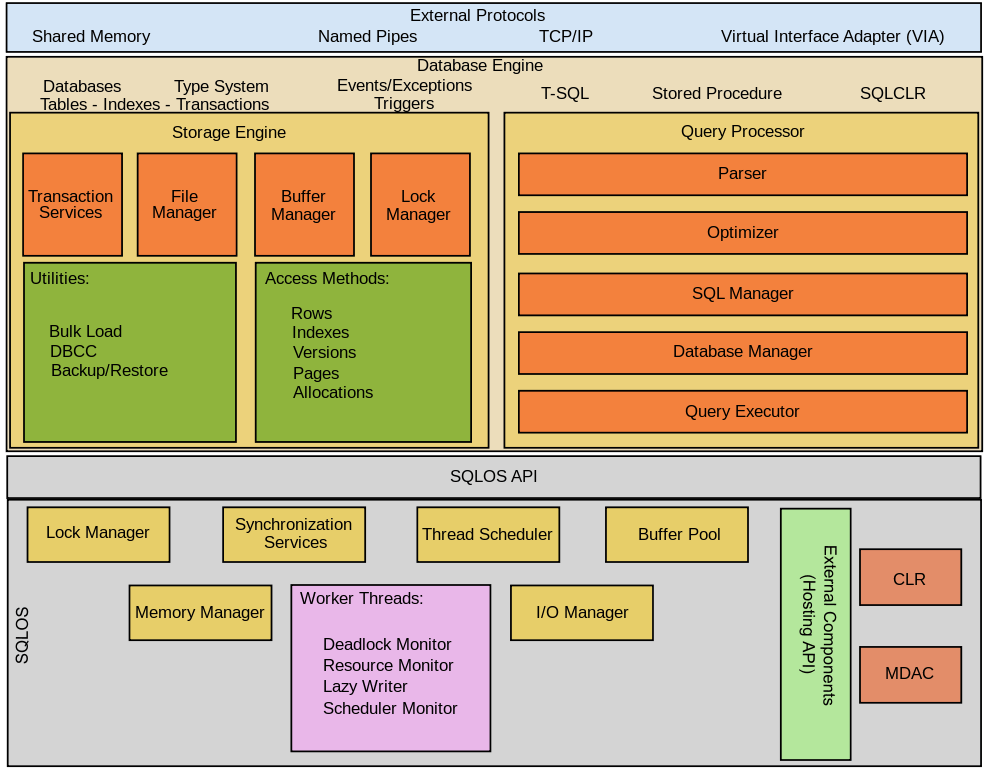
Microsoft SQL Server
SQL Server is a relational database management system (RDBMS) developed by Microsoft – Built on top of SQL, it is also tied to Transact-SQL (T-SQL), Microsoft’s own variant of SQL that adds a set of proprietary programming constructs. Its main purpose is as a database server, that is to say for storing and retrieving data requested by other applications, either locally or over a network including the internet.
Microsoft has (in the past) tried to tie down SQL Server to the Windows environment, in a similar way to their attempt to essentially create essentially their own proprietary version of Java in the form of C#, which was also geared towards tying developers to their operating systems. However in 2016, Microsoft made SQL server available on Linux, and it then became generally available in 2016 to run on both Windows and Linux.
“””
SQL Server supports different data types, including primitive types such as Integer, Float, Decimal, Char (including character strings), Varchar (variable length character strings), binary (for unstructured blobs of data), Text (for textual data) among others. The rounding of floats to integers uses either Symmetric Arithmetic Rounding or Symmetric Round Down (fix) depending on arguments: SELECT Round(2.5, 0) gives 3.
Microsoft SQL Server also allows user-defined composite types (UDTs) to be defined and used. It also makes server statistics available as virtual tables and views (called Dynamic Management Views or DMVs). In addition to tables, a database can also contain other objects including views, stored procedures, indexes and constraints, along with a transaction log. A SQL Server database can contain a maximum of 231 objects, and can span multiple OS-level files with a maximum file size of 260 bytes (1 exabyte).The data in the database are stored in primary data files with an extension .mdf. Secondary data files, identified with a .ndf extension, are used to allow the data of a single database to be spread across more than one file, and optionally across more than one file system. Log files are identified with the .ldf extension.
“””
SQL Server Data Types
Data types in SQL Server are organized into the following categories:
| Exact numerics | Unicode character strings |
| Approximate numerics | Binary strings |
| Date and time | Other data types |
| Character strings |
SOURCE: https://docs.microsoft.com/en-us/sql/t-sql/data-types/data-types-transact-sql?view=sql-server-ver15
T-SQL
Transact-SQL or T-SQL is a proprietary extension to SQL developed by Sybase and Microsoft. It expands on the functionality of basic SQL in a variety of ways including bringing in local variables, procedural programming capabilities, and adding various support functions for strings, dates, and math operations. There are also some changes in the use of the DELETE and UPDATE statements in T-SQL.
Features of T-SQL
Temporary Tables
The name of the temporary table starts with a hash symbol (#). For example, the following statement creates a temporary table using the SELECT INTO statement:
|
1 2 3 4 5 6 7 8 |
SELECT product_name, list_price INTO #adidas_products --- temporary table FROM production.products WHERE brand_id = 12; |
Stored Procedures
A Stored Procedure is a piece of prepared SQL code that you can save such that the code can be reused over and over again. You can also pass parameters to a stored procedure so that the stored procedure can act based on the parameter value(s) that are passed to it. We’ve also see Stor Procs in Oracle-based solutions.
“Stored procedures…allow one to move code that enforces business rules from the application to the database. As a result, the code can be stored once for use by different applications. Also, the use of stored procedures can make one’s application code more consistent and easier to maintain. This principle is similar to the good practice in general programming in which common functionality should be coded separately as procedures or functions”()
The basic syntax of a stored procedure is as follows:
|
1 2 3 4 |
CREATE PROCEDURE procedure_name -- or for shorter syntax CREATE PROC AS sql_statement GO; |
T-SQL includes support for Stored Procedures which act as executable server-side routines where there is the ability to pass in parameters to these.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE PROCEDURE uspProductList AS BEGIN SELECT product_name, list_price FROM production.products ORDER BY product_name; END; |
http://www.sqlservertutorial.net/sql-server-stored-procedures/basic-sql-server-stored-procedures/
Some of the most important advantages of using stored procedures are summarised as follows:
- Because the processing of complex business rules can be performed within the database, significant performance improvement can be obtained in a networked client-server environment (refer to client-server chapters for more information).
- Since the procedural code is stored within the database and is fairly static, applications may benefit from the reuse of the same queries within the database. For example, the second time a procedure is executed, the DBMS may be able to take advantage of the parsing that was previously performed, improving the performance of the procedure’s execution.
- Consolidating business rules within the database means they no longer need to be written into each application, saving time during application creation and simplifying the maintenance process. In other words, there is no need to reinvent the wheel in individual applications, when the rules are available in the form of procedures.
().
DECLARE, SET and SELECT
|
1 2 3 4 5 6 |
-- Variables in SQL Server DECLARE @variable1 NVARCHAR(30); SET @variable1 = 'Dave'; SELECT @variable1 = Name FROM Sales.Store WHERE CustomerID = 100; |
FLOW CONTROL
TRY CATCH
This new exception handling behaviour was introduced by Microsoft in SQL Server 2005, with the purpose of enabling developers to simplify their code ().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-- Example of "TRY CATCH" in SQL Server -- begin transaction BEGIN TRAN; BEGIN TRY INSERT INTO MYTABLE(NAME) VALUES ('ABC'); INSERT INTO MYTABLE(NAME) VALUES ('123'); -- commit the transaction COMMIT TRAN; END TRY BEGIN CATCH -- roll back the transaction in the event of an error ROLLBACK TRAN; END CATCH; |
ETC
SQLite
“SQLite is an open source embedded relational database management system or RDBMS contained in a C programming library. Relational database systems are used to store data in large tables.
In contrast to other popular RDBMS products like Oracle Database, IBM’s DB2, and Microsoft’s SQL Server, SQLite does not require any administrative overhead or any setup complexity.
As the other databases are working as a standalone process, SQLite is not working as a standalone process. You have to link it with your application statically or dynamically.
SQLite uses dynamically and weakly typed SQL for column. It means you can store any value in any column, regardless of the data type. SQLite implements most of the SQL92 standard” (Ref#: F).
Features of SQLite
- Serverless
- Zero Configuration
- Cross-Platform
- Self-Contained (A single library contains the entire database system, which integrates directly into a host application).
- Transactional (ACID-compliant – all queries are Atomic, Consistent, Isolated, and Durable).
- Light-weight
- Familiar language
- Highly Reliable
Playing With sqlite3
To open sqlite3 from our mac Terminal (or iTerm) we can just type sqlite3 (assuming it’s installed)
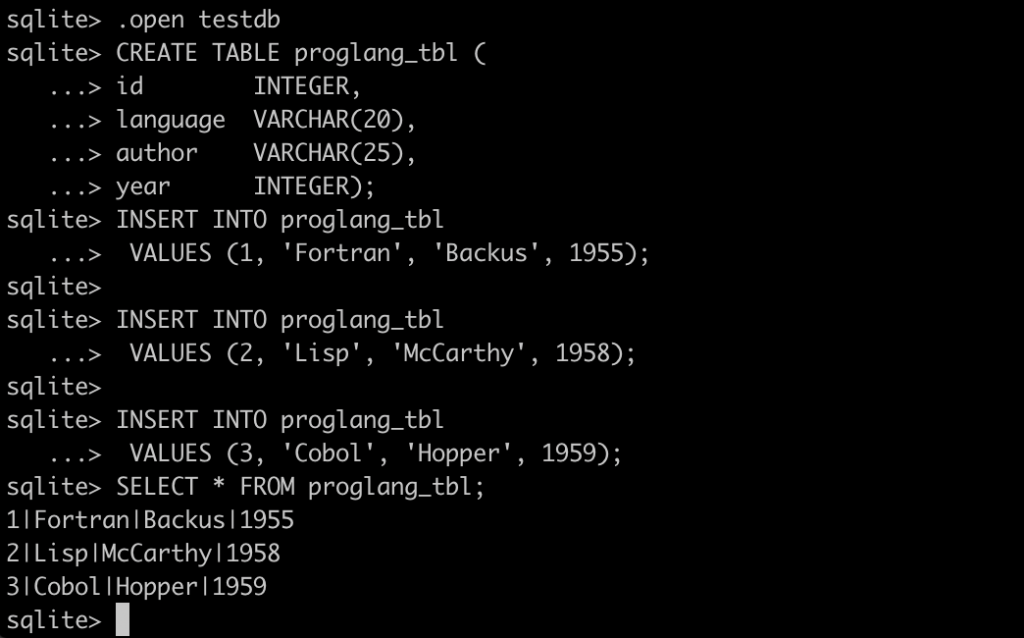
Source: SQL Primer
Default Constraint in SQLite
Syntax
|
1 2 3 4 |
-- Create a table with 3 elements, one of which is given a default value CREATE TABLE tablename (colum1 INTEGER PRIMARY KEY, column2 TEXT NOT NULL, column3 INTEGER DEFAULT defaultvalue); |
Then when we don’t provide all the values, the DEFAULT one will be automatically populated for us:
|
1 2 3 4 5 |
sqlite> INSERT INTO BOOK (Book_id,Book_name) VALUES(1,'RAMAYANA'); sqlite> SELECT * FROM BOOK; Book_id Book_name Price ---------- ---------- ---------- 1 RAMAYANA 100 |
Tools For Use With XCode / iOS / FMDB
1/ openSim (or …) allow you to easily find the folder your sims are using, where you can then monitor the database file.
2/ SQLiteStudio
3/ DB Browser for SQLLite
More Topics
- The graph-oriented model The NoSQL movement. Implementing ER models in a graph-oriented database. Graph databases: optimised for computing transitive closure. Path-oriented queries.
- The document-oriented model Semi-structured data (XML, JSON). Document-oriented databases. Embracing data redundancy: representing data for fast, application-specific, access.
- The multi-dimensional model. Data cubes, star schema, data warehouse.
Neo4j – Neo4j is a system for using graph databases, these are not relational databases.
References
A: https://en.wikipedia.org/wiki/Relational_database
B: https://www.appcoda.com/fmdb-sqlite-database/
C: https://medium.com/@dkw5877/sqlite-with-fmdb-5f6e4626249a
D: https://www.tutlane.com/tutorial/sqlite/sqlite-default-constraint
E: https://www.tutlane.com/tutorial/sqlite/sqlite-syntax
F: https://www.tutlane.com/tutorial/sqlite/sqlite-introduction
G: https://www.cl.cam.ac.uk/teaching/1112/Databases/db_2012_2up.pdf
H: https://www.cl.cam.ac.uk/teaching/1920/Databases/
I: https://slideplayer.com/slide/6877152/
J: https://www.sciencedirect.com/topics/computer-science/query-optimization
K: http://www.sqlservertutorial.net/sql-server-stored-procedures/
L: https://www.cs.uct.ac.za/mit_notes/database/htmls/chp11.html#multilevel-indexes
M: https://www.cs.uct.ac.za/mit_notes/database/pdfs/chp01.pdf
N: https://www.cs.uct.ac.za/mit_notes/database/pdfs/chp05.pdf
O: https://www.cs.uct.ac.za/mit_notes/database/pdfs/chp06.pdf
P: https://www.cs.uct.ac.za/mit_notes/database/pdfs/chp08.pdf
Q: https://www.cs.uct.ac.za/mit_notes/database/pdfs/chp09.pdf
R: https://www.cl.cam.ac.uk/teaching/1819/Databases/database_2018.pdf
S: https://www.cl.cam.ac.uk/teaching/1920/Databases/database_2019_2up.pdf
T: https://www.cl.cam.ac.uk/teaching/1920/Databases/relational-tutorial.html
U: https://www.youtube.com/watch?v=sRwn1A8T6T4
Definitions
resultset: “Set theory is a branch of discrete mathematics that deals with a collection of objects. There is a lot of conceptual overlap between set theory and relational database concepts. It is no wonder that the output of a query is frequently called a resultset“.
view: A view is a query that can be used like a table. “Think of it as a virtual table that stores for the viewer’s convenience a pre-computed resultset. It does not truly exist like a base table but provides a different angle to view the data without the tedium of details” (SQL Primer).
![]()
Comments